개발자에게 CP949라고 하면 으레 EUC-KR을 기반으로 MS에서 확장 정의한 코드페이지를 생각할 것이다.
PC에서 한글을 표현하는 방법으로서 사실상 표준으로 사용되고 있고[footnote]아직 유니코드로 완전히 이전되지 못했다. 인터넷만 봐도 여전히 많이 쓰이는데 뭐…[/footnote], 당장 위키피디아CP949 페이지를 들어가봐도 Microsoft’s implementation으로 문서가 시작한다.
위키피디아의 CP949 Map
여튼. 어쩌다보니 MBCS 텍스트의 코드페이지를 바꿔 해석해야 하는 코드스냅이 필요하여 자바로 코드를 짜게 되었다.
예를 들면 이런거다. Shift-JIS에서 특수문자 “☆”은 0x8199 로 매핑되는데, 이를 CP949로 해석하면 “걲”이 된다.
이런 사유로, Shit-JIS에서 “☆新年☆”이라는 문자열이 CP949에서 “”걲륷봏걲”이 되어버린다. 허허허…
필요한 코드는 이를 바로잡아주는 코드인데, 사실 코드 자체는 정말 간단하다.
자바는 문자열 처리에 UTF-16BE를 사용하며, 필요한 경우 이를 꽤나 편리하게 바이트 스트림으로 변경이 가능하며,
반대로 바이트 스트림에서 코드페이지를 지정하여 문자열을 만들어낼 수도 있다.
public static String convertCodepage(String src, Charset cpCurrent, Charset cpNew)
{
byte[] b = src.getBytes(cpCurrent);
String n = new String(b, cpNew);
// 사실 한 줄로 줄여도 된다.
return new String(src.getBytes(cpCurrent), cpNew);
}
이런 코드를 짜고, 파라미터로 CP949를 적용하면 잘 될 줄 알았다.
근데 안 된다 -_-
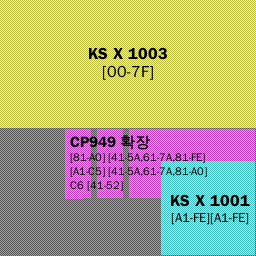
차근히 찾아보니 자바에서 CP949는 MS 구현이 아니랜다. Charset 클래스에서 CP949는 x-IBM949의 동의어로 처리된다.
흠 그런가? 하고 좀 더 찾아보니, x-IBM949는 단지 EUC-KR에 확장 ASCII 코드를 몇 개인가 더 붙여둔 것 같다.
즉슨, 안타깝게도 x-IBM949는 KS-X-1001[footnote]일부에게는 KS-C-5601이 더 익숙할지도 모르겠다.[/footnote]에 정의된 8,848글자의 한글만 표현할 수 있으며, 이를 벗어나는 이른바 “확장 한글”[footnote]CP949에서 추가로 정의된 글자들. 예를들면 “똠”이나 “쓩”, “뷁” 같은거[/footnote]은 표기할 수 없다.
그렇다면 자바에서 MS 확장을 사용할 수는 없는걸까? 물론 쓸 수 있다. MS 확장 구현은 “MS949″로 정의되어 있다.
위의 코드에서도, 파라미터만 MS949로 변경하니 의도한대로 잘 작동하는 것을 확인할 수 있었다.
다만 안타까운 사실은, 이것을 찾아내는데 장장 세 시간이 넘게 걸렸다는 점 정도일까. 선마이크로시스템즈 나쁜색기들.